
The previous post mapped the landscape - which sports use which approaches and why. This post goes one level deeper into the mathematical foundations that underlie all win probability models. The methods described here are not sport-specific. They are the building blocks that get adapted, extended, and combined differently depending on the game structure.
Logistic regression: the universal starting point
Nearly every win probability model either uses logistic regression directly or builds on top of it. The reason is straightforward: win probability is a binary outcome (win or lose), and logistic regression is the standard method for modeling binary outcomes as a function of continuous predictors.
The logistic function maps any real-valued input to a probability between 0 and 1:
P(win) = 1 / (1 + e^(-z))
where z is a linear combination of predictor variables:
z = β₀ + β₁x₁ + β₂x₂ + ... + βₖxₖ
In a win probability context, the predictors typically include score differential, time remaining, and sport-specific state variables. The coefficients β₁ through βₖ are estimated from historical play-by-play data using maximum likelihood estimation.
For example, a minimal basketball win probability model might use:
z = β₀ + β₁(score_diff) + β₂(time_remaining) + β₃(possession) + β₄(score_diff × time_remaining)
The interaction term β₄(score_diff × time_remaining) is critical. A 10-point lead means something very different with 30 minutes remaining than with 30 seconds remaining. Without the interaction, the model treats a point of score differential as equally important regardless of when it occurs.
Locally weighted logistic regression
Standard logistic regression assumes the relationship between predictors and outcome is the same across the entire dataset. This is a poor assumption for win probability, where the dynamics change dramatically as the game progresses.
Mike Beuoy’s Inpredictable model addressed this by using locally weighted logistic regression (LOESS applied to a logistic framework). Rather than fitting a single model to all game states, the approach fits a separate logistic regression for each prediction point, weighting nearby observations more heavily.
For a target game state s*, the weight assigned to training observation i with state sᵢ is:
wᵢ = K(d(s*, sᵢ) / h)
where K is a kernel function (typically tricube), d is a distance metric in the state space, and h is the bandwidth parameter controlling the locality of the fit. The logistic regression is then fit with these weights applied to the likelihood function.
Brian Burke took a related but different approach for college basketball: fitting separate logistic regressions for fixed time intervals - one per 10-second interval from 1-40 minutes remaining, one per 2-second interval from 30-60 seconds, and one per 1-second interval for the final 30 seconds. This segmentation approximates the continuous adaptation of locally weighted regression with discrete bins.
Both approaches address the same problem: the logistic regression coefficients are not constant over the course of a game.
Incorporating prior information: Vegas spreads
One of Beuoy’s key innovations was incorporating the pregame Vegas point spread as a predictor variable. The spread encodes the market’s assessment of the relative team quality before the game begins. Adding it to the model:
z = β₀ + β₁(score_diff) + β₂(time_remaining) + β₃(possession) + β₄(spread) + ...
This significantly improves predictions, particularly early in the game when the score provides limited information about which team is better. A team trailing by 3 points in the first quarter of a game where they were favored by 10 is in a very different position than a team trailing by 3 that was a 10-point underdog. Without the spread, both states map to the same win probability.
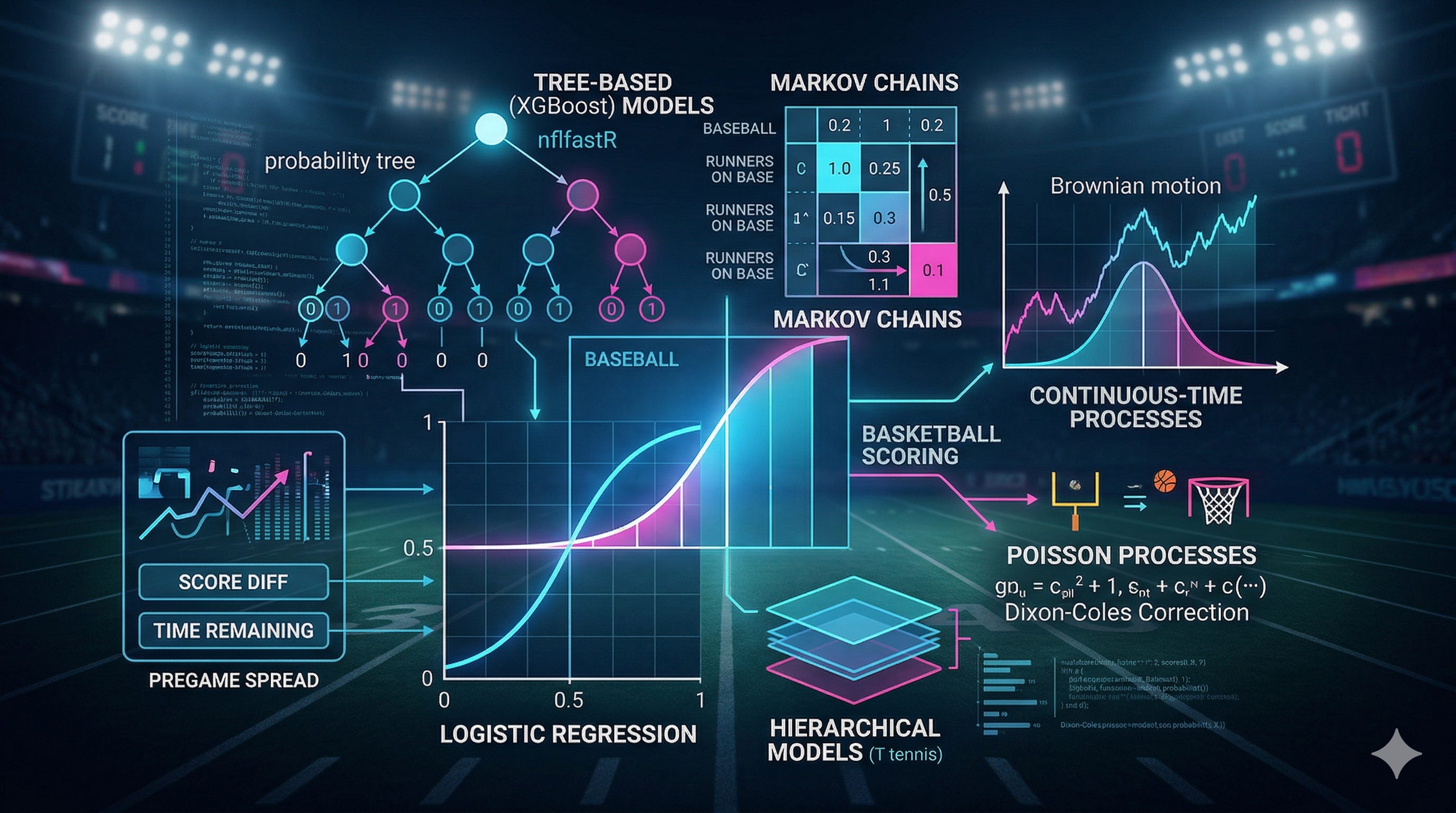
Markov chains: modeling discrete state transitions
A Markov chain is a stochastic process where the probability of transitioning to the next state depends only on the current state, not on the sequence of states that preceded it. This property - the Markov property - is formally stated as:
P(Sₙ₊₁ = sⱼ | Sₙ = sᵢ, Sₙ₋₁ = sₙ₋₁, ..., S₀ = s₀) = P(Sₙ₊₁ = sⱼ | Sₙ = sᵢ)
In sports, the Markov property holds when the current game state contains all the information needed to predict future states. Baseball satisfies this almost perfectly: given the inning, outs, baserunners, and score, the history of how we got to this state is irrelevant to the probability of winning.
Transition probability matrices
For a sport with n discrete states, the Markov chain is defined by an n × n transition probability matrix P, where entry Pᵢⱼ is the probability of transitioning from state i to state j:
P = [Pᵢⱼ] where Pᵢⱼ = P(Sₙ₊₁ = j | Sₙ = i)
Each row sums to 1. In baseball, the states are the 24 base-out combinations within a half-inning (plus the absorbing state of 3 outs), and the transitions correspond to the outcomes of plate appearances - single, double, strikeout, fly out, etc.
The transition probabilities are estimated from historical data. Given a large enough dataset of play-by-play records, you count the frequency of each transition and normalize:
P̂ᵢⱼ = (number of transitions from i to j) / (total transitions from i)
Absorbing states and win probability computation
Win probability from a Markov chain is computed by propagating forward through the transition matrix. Some states are absorbing - once the game enters them, it stays there. The end of a baseball half-inning (3 outs recorded) is an absorbing state within the half-inning Markov chain.
For the full game, the computation proceeds recursively:
In the current half-inning, use the transition matrix to compute the probability distribution over runs scored before 3 outs
Given the runs scored, update the score differential
Move to the next half-inning and repeat
Continue until the game ends (bottom of the 9th or later, with the home team leading)
The win probability at any state is the sum over all future paths of the probability of reaching a winning terminal state:
WP(sᵢ) = Σⱼ Pᵢⱼ · WP(sⱼ)
This recursion terminates at the absorbing states (game over, team A wins or team B wins).
Hierarchical Markov chains: tennis
Tennis extends the Markov framework to a hierarchical structure. The match is modeled as nested Markov chains operating at different levels:
Point level: Given the probability p that the server wins a point, the probability of winning a game on serve is computed from the deuce structure. Before deuce, the game follows a finite sequence. At deuce, the game enters a recursive state where the server needs to win two consecutive points. The closed-form solution for the probability of winning a game on serve is:
P(game | serve) = p⁴(1 + 4q + 10q²) + 20p³q³ · [p² / (p² + q²)]
where q = 1 - p.
Game level: Given game-win probabilities on serve and return, the probability of winning a set follows a similar recursion through the games within a set, including the tiebreak at 6-6 (in most formats).
Set level: Given set-win probabilities, the match-win probability follows from the best-of-three or best-of-five format.
Each level is a separate Markov chain, and the levels compose: the output of the lower level (point-win probability) feeds into the input of the next level (game-win probability), and so on upward.Brownian motion: continuous-time stochastic processes
While Markov chains model discrete state transitions, Brownian motion models continuous evolution. It was introduced to sports scoring by Stern (1994), who showed that the score differential in a basketball game evolves approximately as:
X(t) = μt + σB(t)
where:
X(t) is the score differential at time t (positive means the home team leads)
μ is the drift parameter, reflecting the difference in team quality (positive μ means the home team is better)
σ is the diffusion parameter, reflecting the randomness in scoring
B(t) is standard Brownian motion (a continuous-time stochastic process with normally distributed increments)
The score differential at time t follows a normal distribution:
X(t) ~ N(μt, σ²t)
Given a current score differential d at time t in a game of total duration T, the win probability for the leading team is:
P(win | d, t) = Φ((d + μ(T - t)) / (σ√(T - t)))
where Φ is the standard normal CDF.
Practical implications
The Brownian motion model captures several empirical features of basketball scoring:
Score differential variance grows linearly with time: The spread of possible score differentials widens as the game progresses, consistent with σ²t
Lead changes follow predictable patterns: The expected number of lead changes in a game between evenly matched teams can be derived from the zero-crossing properties of Brownian motion
Scoring intervals are approximately exponential: Gabel and Redner (2011) showed that the time between scoring events in the NBA follows an exponential distribution, consistent with a Poisson process driving the Brownian motion increments
The model breaks down in the final minutes when strategic behavior (intentional fouling, clock management) violates the stationarity assumption. The drift and diffusion parameters are not constant when teams fundamentally alter their playing style based on the score and clock.
Poisson processes: modeling rare events
For low-scoring sports like soccer and hockey, the Poisson distribution provides the natural framework. A Poisson process models the number of events (goals) occurring in a fixed interval, given a constant average rate:
P(k goals in time t) = (λt)ᵏ e^(-λt) / k!
where λ is the scoring rate (goals per unit time) and k is the number of goals.
Application to win probability
For a game at time t with score a - b (home team has a goals, away team has b) and remaining time T - t:
Model the remaining goals for each team as independent Poisson random variables with parameters λ_home(T-t) and λ_away(T-t)
Compute the probability of each possible final score
Sum the probabilities of all final scores where the home team wins
P(home win) = Σᵢ Σⱼ P(home scores i more) · P(away scores j more) · I(a+i > b+j)
where I is the indicator function.
The scoring rates λ_home and λ_away can be estimated from pre-game team strength ratings, in-game expected goals (xG) accumulation rates, and historical league averages adjusted for home advantage.
The Dixon-Coles correction
The basic Poisson model assumes independence between the two teams’ goal-scoring processes. Dixon and Coles (1997) showed that this independence breaks down for low-scoring outcomes. Their correction introduces a parameter τ that adjusts the joint probability of specific scorelines:
For home goals = x and away goals = y:
P(x, y) = τ(x, y, λ_home, λ_away, ρ) · P_Poisson(x; λ_home) · P_Poisson(y; λ_away)
The correction factor τ depends on a parameter ρ that captures the correlation between teams’ scoring in low-scoring games (typically 0-0, 1-0, 0-1, 1-1 scorelines). When ρ = 0, the model reduces to independent Poisson. Empirically, ρ is small but statistically significant, and including it improves out-of-sample prediction accuracy.
Expected goals (xG) as Poisson intensity
Modern implementations replace the constant scoring rate λ with a dynamic estimate based on expected goals. Each shot attempt is assigned a probability of being scored based on shot location, shot type, assist type, game state, and other features. The cumulative xG through a game provides a running estimate of each team’s attacking quality:
λ̂_home(t) = xG_home(t) / t
This allows the Poisson model to update in real time based on the quality of chances being created, not just the goals that have actually been scored. A team generating 2.5 xG but only scoring 1 goal is modeled differently than a team generating 0.8 xG and scoring 1 goal, even though the scoreline is identical.
Tree-based and ensemble methods
When the state space is too large for lookup tables and the interactions between variables are too complex for parametric models, machine learning methods - particularly gradient-boosted decision trees - have become the standard.
Gradient-boosted trees (XGBoost)
The nflfastR win probability model for football uses XGBoost, which builds an ensemble of decision trees sequentially, with each tree correcting the errors of the previous ensemble:
F(x) = Σₘ fₘ(x)
where each fₘ is a decision tree and the sum produces the final prediction. The logistic loss function ensures the output can be interpreted as a probability:
L = -Σᵢ [yᵢ log(p̂ᵢ) + (1-yᵢ) log(1-p̂ᵢ)]
where yᵢ is the actual outcome (1 for win, 0 for loss) and p̂ᵢ is the predicted probability.
Why trees work for football
Decision trees naturally capture the interaction effects that dominate football game states. The tree can learn that 4th-and-1 at the opponent’s 2-yard line with a 3-point deficit and 30 seconds left is very different from 4th-and-1 at the opponent’s 2-yard line with a 3-point lead and 30 seconds left. These interactions don’t need to be specified by the modeler - the algorithm discovers them from data.
The nflfastR model uses features including: seconds remaining in the half, score differential, timeouts remaining (offense and defense), whether the team receives the second-half kickoff, yard line, down, yards to go, and an expected points variable that captures field position value.
ESPN’s ensemble approach
ESPN’s win probability models use ensemble methods that combine multiple model types. The specifics are proprietary, but the general approach involves training several different model architectures on the same data and averaging their predictions, weighted by each model’s historical accuracy. This reduces variance and produces more calibrated probability estimates than any single model.
Evaluating win probability models
A win probability model that predicts every game state at 50% is perfectly calibrated (on average) but useless. A model that predicts 90% confidence in every outcome will be right 90% of the time if it’s well-calibrated, but only if those 90% predictions actually win 90% of the time. Evaluating model quality requires metrics that capture both calibration and discrimination.
Brier score
The Brier score is the mean squared error between predicted probabilities and actual outcomes:
BS = (1/n) Σᵢ (p̂ᵢ - yᵢ)²
where p̂ᵢ is the predicted probability and yᵢ is the outcome (0 or 1). Lower is better. A perfect model scores 0. A model that predicts 50% for every game scores 0.25.
The Brier score can be decomposed into three components:
BS = Reliability - Resolution + Uncertainty
Reliability (lower is better): measures how close predicted probabilities are to observed frequencies.
Resolution (higher is better): measures how much predicted probabilities deviate from the base rate.
Uncertainty (fixed): depends only on the base rate of outcomes in the dataset.
Log loss (cross-entropy)
Log loss penalizes confident wrong predictions more heavily than the Brier score:
LL = -(1/n) Σᵢ [yᵢ log(p̂ᵢ) + (1-yᵢ) log(1-p̂ᵢ)]
A prediction of 99% confidence that turns out wrong is penalized far more than a prediction of 60% confidence that turns out wrong. This makes log loss particularly useful for evaluating predictions at the extremes.
Calibration curves
A calibration curve (reliability diagram) plots predicted probabilities on the x-axis against observed frequencies on the y-axis. A perfectly calibrated model produces a 45-degree line. Deviations reveal systematic biases:
Curve above the diagonal: the model is underconfident (events happen more often than predicted)
Curve below the diagonal: the model is overconfident (events happen less often than predicted)
S-shaped curve: the model is overconfident at extremes and underconfident in the middle (or vice versa)
Calibration in practice
FiveThirtyEight’s RAPTOR model for basketball has a known calibration issue: it overestimates home team win probability, predicting home teams win 70% of the time when the actual rate is approximately 61%.
The nflfastR football model publishes calibration plots showing tight calibration across the probability range, with some deviation at the extremes where sample sizes are small.
Reporting calibration curves alongside point estimates of model accuracy should be standard practice but often isn’t. A model’s Brier score can look good in aggregate while hiding systematic miscalibration in specific game states.
The mathematical taxonomy
These methods are not mutually exclusive. FiveThirtyEight’s basketball model uses Poisson for the main game and a decision tree for the endgame. Football models use Expected Points (a regression-based framework) as a feature within an XGBoost model. The Dixon-Coles soccer model applies a parametric correction to a Poisson base.
The art of win probability modeling is knowing which tools to combine and where each one’s assumptions break down. The sport-specific posts that follow will explore exactly that.
References
Beuoy, M. (2013). “NBA Win Probability Calculator.” Inpredictable.com.
Burke, B. (2007). “Win Probability Model.” Advanced NFL Analytics.
Chen, T. and Guestrin, C. (2016). “XGBoost: A Scalable Tree Boosting System.” Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 785-794.
Dixon, M.J. and Coles, S.G. (1997). “Modelling Association Football Scores and Inefficiencies in the Football Betting Market.” Journal of the Royal Statistical Society: Series C, 46(2), 265-280.
Gabel, A. and Redner, S. (2012). “Random Walk Picture of Basketball Scoring.” Journal of Quantitative Analysis in Sports, 8(1).
Klaassen, F.J.G.M. and Magnus, J.R. (2001). “On the Independence and Identical Distribution of Points in Tennis.” Journal of the American Statistical Association, 96(454), 500-509.
Stern, H.S. (1994). “A Brownian Motion Model for the Progress of Sports Scores.” Journal of the American Statistical Association, 89(427), 1128-1134.
Tango, T.M., Lichtman, M.G., and Dolphin, A.E. (2006). The Book: Playing the Percentages in Baseball. Potomac Books.
Neal Foster is Co-Founder & CTO of SportChartz and Founder & Partner of Vybe Capital.